About
HAN
Dealing with Big Data
Historical Agricultural News topic‐specific search tool responds to the challenge of what has come to be known as “big data”: the overwhelming amount of information that often inundates the searcher. The digitization of primary sources has changed the face of archival research, bringing new opportunities—and new challenges—to scholars and laymen alike. Whether someone is working on an academic history or a family genealogy, materials can often be found as close as a laptop or tablet. But while availability of materials has increased exponentially, the ability to easily utilize these materials has not kept pace.
The Chronicling America database currently contains 10,905,287 pages, and is continually growing as more collections are added. Even using specific dates, locations, and key words, this is a massive amount of information to search. Breaking out a subset of pages, delimited by a specific topic group, allows searchers to bypass non‐essential items. Historical Agricultural News uses the category of “organizations” to narrow the initial search to agriculture‐related organizations, and provides additional search term categories such as Grain Crops, Livestock and Dairy, and Vegetable Crops to further simplify the process. By offering this interface, the search engine weeds out arbitrary results (such as grocery advertisements) that might otherwise clog a research query.1
Historical Agricultural News, then, hopes to achieve several purposes: to make the Chronicling America database more accessible to those interested in agricultural history; to demonstrate a new customizable search algorithm, which could be used for different topics in future search engines; and to make transparent the participation of newspapers in distributing and embedding new paradigms in agricultural science and technology.
Humanities researchers Shawn Graham, Ian Milligan, and Scott Weingart describe both the affordances and the constraints of big data. They point out that access to digital data has changed, and will continue to change, the way that researchers approach information. Among the features of the big data universe that assist researchers, Graham, Milligan, and Weingart cite increased storage space, cloud storage, and ease of access through open source or data sharing. Limitations include content type (for example, scanned images may not be rendered through OCR, and thus not text searchable), restrictions on open access, and copyright issues.
Thus, to build a usable search tool required data with OCR‐rendered text, public domain data, and open access through an API (Application Programming Interface) to the big data. The Chronicling America newspaper collection met all these criteria.
About the Site
Three people are involved in the construction of Historical Agricultural News: Amy L. Giroux, Ph.D., Nathan Giroux, and Marcy L. Galbreath, Ph.D. The idea for Historical Agricultural News as an aide for research emerged from the dissertation research Galbreath was conducting in 2013‐14. The newspapers included in the Chronicling America collection were a tantalizing source of information, but time constraints prevented utilizing the database to its full potential. The ongoing issues of big data usability—large data sets and correspondingly large query returns—made locating and identifying usable data a difficult and frustrating process. Thus the challenge of exploring a theme within Chronicling America while also developing a creative way of using big data immediately lent itself to the research question of “how did the dominant social communications (the newspapers) of the 19th and early 20th centuries help propagate the advance of modern agriculture in the United States?”
To address this question, A. Giroux envisioned an algorithm that could filter a subset of data out of the mass, and then apply additional keyword filters to pull individual articles out of the pages. This not only would locate the keyword, but also call out the exact relevant article from the newspaper page where the keyword is found. In addition, the search would include an option to go directly to the corresponding newspaper image on the Chronicling America site.
N. Giroux designed the algorithm according to the specifications presented by A. Giroux. His algorithm proved to be incredibly flexible; while the subset for Historical Agricultural News was built on keywords associated with agricultural organizations, this new algorithm could be adapted to any subset of search criteria and thus extend its utility beyond this application.
OCR and Readable Text
The data underlying the operability of Historical Agricultural News is made possible by the Library of Congress’ open source API for Chronicling America. Through the API, and because the newspaper pages in the database are text‐readable through OCR, Historical Agricultural News is able to pull raw text data and run a process that queries for specific criteria. Once A. Giroux acquired this subset database she then created a search interface to drill down to a more detailed level, enabling users to customize the search within that subset. This interface is viewable on full size PC screens, and also on mobile devices. Users are provided with a search template and suggested terms, along with the option to enter their own key words. The default on organizations is set to “all,” but this can be modified to satisfy user criteria.
Even though the issue of searchable text identified by Graham, Milligan, and Weingart has been addressed through OCR, the problem of “dirty” or “noisy” text (Chen, Luettin, and Shearer; Teahan, Inflis, Cleary, and Holmes), or “dirty” OCR (Shaw; Treloar) remains. Noisy or dirty text refers to poor original images that hamper OCR recognition, while dirty OCR is OCR produced without direct human intervention in the form of editing or revision. Because of the age and volume of material scanned and subsequently rendered into text through Chronicling America, the database articles Historical Agricultural News is drawing from do not always produce readable text or recognizable words. This is where context becomes important: by grouping search categories, the results thus obtained can usually be determined as appropriate or not, and looking at the original document (provided through a link in the Results page) usually clarifies the content. As with any archival work, some level of interpretation by the researcher is usually necessary.


In addition to dirty OCR, another issue encountered in the design of the website concerned the layout of the original newspaper pages. The program that was created to pull articles from the bulk data sets out of the Library of Congress Chronicling America API worked by identifying article titles or headers. The newspaper pages from which these articles were selected used various formats for article titles, such as bold text, all capitalization, and different fonts, but they also sometimes employed these same effects for subtitles, names, and the first line of text. The occasional result is that the algorithm selects identifying text other than the original title. The articles thus pulled still contain relevant information, and in a future release of the algorithm, the rules for selection of titles may be expanded.
Maps
An additional feature on the Results page are heat maps detailing the frequency of publication for the associated search terms. Locations of land‐grant universities are also noted on the maps, further contextualizing the communication taking place on these topics.
The use of heat map overlays is an effective way to visualize large data sets, as the different color fields immediately communicate concentrations or density of data points (Gonzalez, et al.; Mashima, Kobourov, and Hu; Trame and Keßler). When represented as comparisons of how many times a topic occurs over time, for example, a high frequency of newspaper articles will appear “hotter,” or redder, in a geographic area. Here is an example:
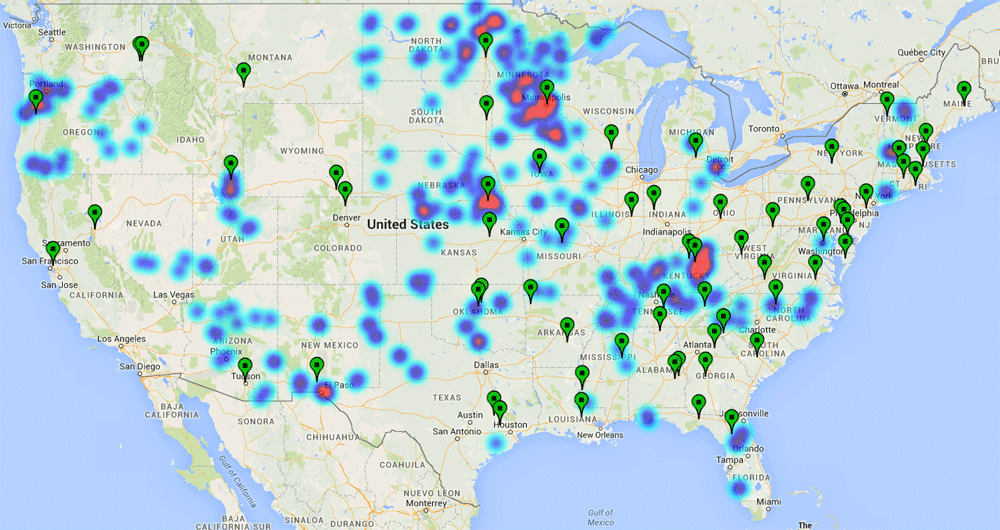
This map shows newspaper articles published between 1912–1922 with the subject of all organizations, and mentions of corn or sheep. Heat areas are represented in the concentric areas of aqua, blue, dark blue, and red. Pins represent the land-grant colleges in operation at that specific time.
Current Site Statistics
Data as of 19 June 2017.
1 Not visible, but added in the search engine, the term “crop” has been added to individual grain and vegetable entries to filter advertisements out of the results.